
前言
之前只是知道能够触发getter或setter,但是却不知道为什么,现在就来结合源码分析一下。
parse和parseObject的区别
这个其实相当于结论了,先总结一下,看源码的时候能够更清楚一点。
- 就返回的类型比较:
parse返回的是反序列化的类本身,而parseObject返回的是JSONObject类。
也就是说parse(jsonString)返回Student类,parseObject(jsonString)返回JSONObject类。
不过parseObject(jsonString, Student.class)返回的就是Student类了。
- 就setter方法调用上:
如果对应的字段存在setter方法,且该setter方法满足:非静态私有函数,返回类型为void或类本身,参数个数为一个。
那么parse和parseObject(这里可以有一个或多个参数)的执行结果一样,即,调用所有满足上述条件的setter方法。
- 就getter方法调用上:
如果对应的字段存在getter方法,且该getter方法满足:非静态私有函数,返回值类型继承自Collection或Map或AtomicBoolean或AtomicInteger或AtomicLong,无参数,并且该字段没有setter方法(不然在JavaBeanInfo.build()的时候会先放setter方法,导致getter方法放不进,后面会分析)。
那么parse和parseObject(这里需要有两个以上的参数,即不能只有jsonString)的执行结果一样,即,调用所有满足上述条件的getter方法。
parseObject(jsonString) 这种单参的情况会有所不同。除了像上面一样会调用符合条件的getter,还会再次调用一遍所有getter方法。这是因为parseObject(String text)会调用JSON.toJSON()。可以在getter方法上打个断点,然后再看前面的调用栈。
- 小结一下:
parse和多参parseObject都会调用符合条件的setter和getter。
单参parseObject除了上面的,还会再调用一遍所有getter。
正式分析
参考代码
首先,确保你的实体类里存在一个只有getter方法的字段,不然后面的derializer会变成ASMDerializer,这样分析流程就不一样了。
我这里用的fastjson1.2.24
这里给出一个实体类的示例:
1 | import java.io.IOException; |
然后反序列化可以用这个:
1 | import com.alibaba.fastjson.JSON; |
这里先测试parse,parse和多参parseObject的结果是一样的。
调试流程
parse
我们直接在ParserConfig的526行打断点:

前面的流程不是很重要,不过还是建议自己看一遍,这里我结合调用栈稍微讲一下:

一开始就是不断parse,业务层层包装,解析json数据,最终我们这里的json数据需要get一个Deserializer去反序列化,最后找到的Deserializer是一个JavaBeanDeserializer,然后就要去build,即重构JavaBean的内容,包括有哪些setter方法,哪些字段,哪些getter方法。我们重点来看一下build的过程。
首先,获得json类中的Field,Method,DefaultConstructor,可以自己去看一下变量里的信息:注意,由于是getMethods,所以private方法无法获取。
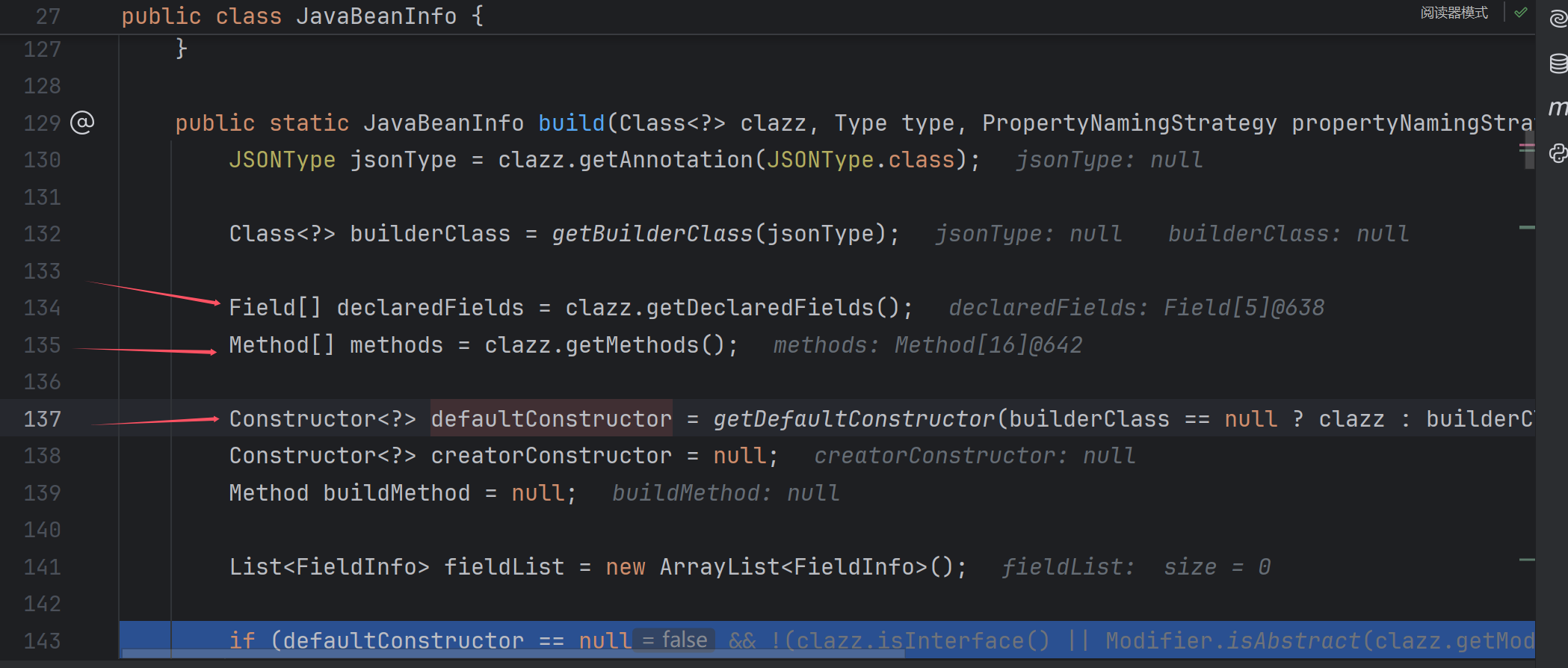
接下来,是对Method的一个遍历,这个很重要:

先做四个判断,方法名长度大于4,方法不能是静态的,方法返回类型为void或返回类型是这个类本身(这里是Student),方法的参数数量为1,只有这样才不会continue。这些满足条件的setter其实就是我们一开始总结的。可以发现setName是符合条件的,继续步过:

这里需要满足方法开头为set,之后就会取出字段名,这里是name。
最后,通过add,把刚刚得到的方法名,字段名等信息包装成FieldInfo,并存入fieldList:
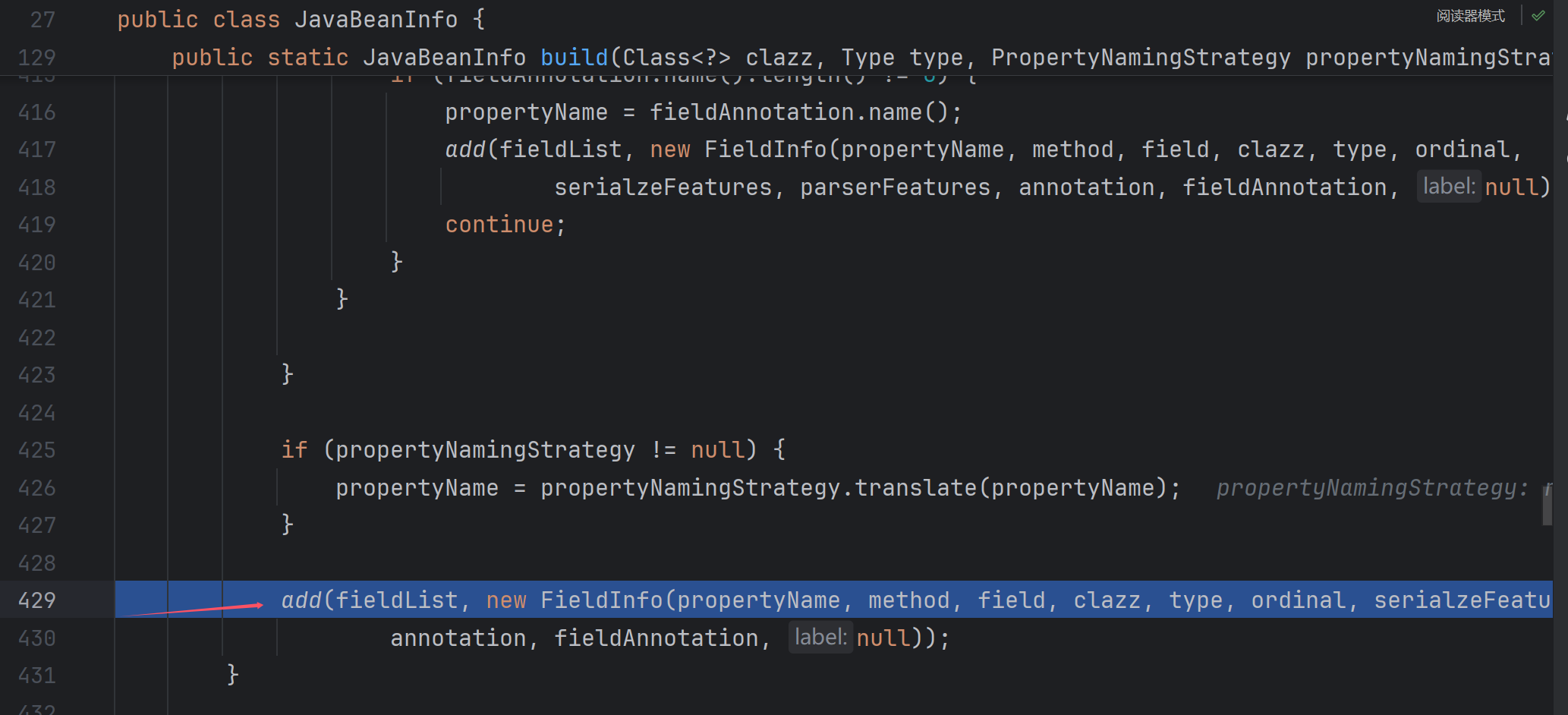
接下来就是循环重复,所以我们直接在下面打断点:

不过由于这里是get public static fields,我们的Student并没有,所以会直接跳到下一个循环:
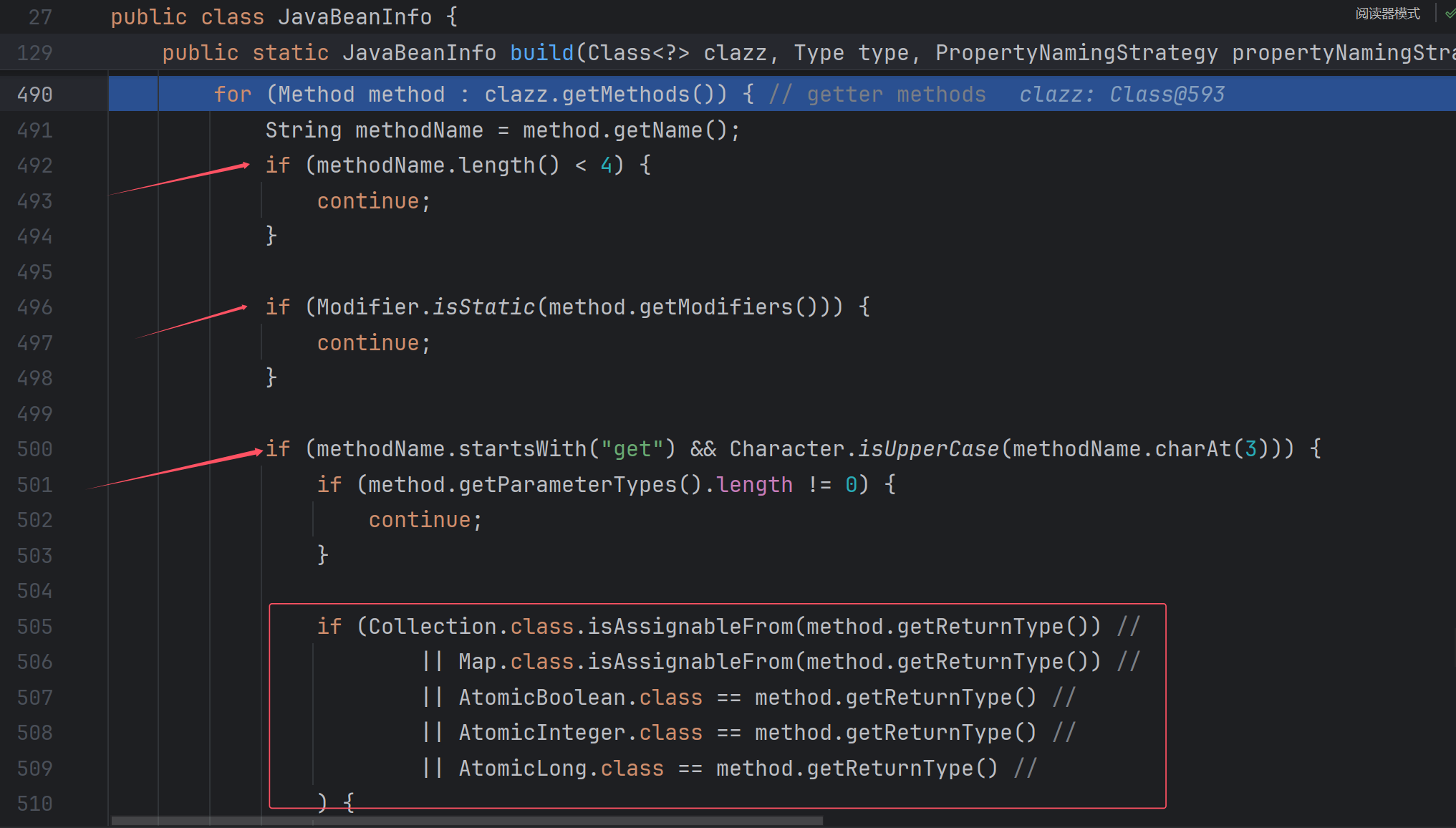
这里跟第一个循环很像,只不过是针对getter的,条件其实就跟一开始总结的一样。
下面这一行很重要:

如果一开始已经把setter存入fieldList,那么同一个字段的getter方法就存不进fieldList了,这就是为什么一个字段必须只存在getter方法,他的getter方法才会被调用。
现在回到createJavaBeanDeserializer方法下:

这里properties属性只有getter方法,这样asmEnable才会被设置为false,这样才不会进入ASM机制。
接下来直接回到DefaultJSONParse.parseObject(),368行:

跟进这个deserialze,这里我直接在setter方法上打断点了,这样往前看调用栈就行:

这样就可以很容易看出为什么会调用getter,setter了,这里不多讲了。
同时也可以发现,parse和parseObject其实最终都会走到DefaultJSONParser.parseObject(),也就是都走到parseObject。
parseObject
来看看为什么单参parseObject会调用所有getter
把下面的注释掉就行。

在这里打个断点:

运行到新打的断点,我这里还是选择在Student上打断点,然后反过来看调用栈:

实际上还是用到了之前的FieldInfo,不过这里的获取序列化器的过程用到ASM机制,这个比较复杂,这里不做解释,感兴趣的可以在这里打断点去调试:

总结
这里主要分析了一下parse和parseObject在什么时候会调用getter,setter。也算是自己第一次分析组件源码吧,当时花了大半天。
总结一下fastjson反序列化的机制:
1、通过字符串的截取,将你指定的类加载为Class对象
2、尝试获取反序列化器,如果不是默认的几个基本数据类型,则会被当成普通的JavaBean,从而去创建JavaBean反序列化器
3、在创建JavaBean反序列化器的过程中,会构建JavaBeanInfo,里面会选取符合要求的Field及其对应方法,并将其添加到fieldList里,这是决定getter,setter调用的关键
4、获取到反序列化器后,开始反序列化过程,通过反射调用setter还原对象,并根据情况调用getter方法
5、如果是单参的parseObject,最后返回的就是jsonObject。由于jsonObject能通过toJSONString还原成json格式,所以JSON.toJSON里一定调用了getter方法。